
Claude Opus 4.6 just broke the METR graph. The benchmark designed to track progress towards the singularity can’t keep up.
Epistemic status: High confidence on the reported numbers and trend direction. Moderate confidence on the extrapolation. METR themselves urge caution on the exact figures - I agree on the figures and disagree that caution is the right takeaway from the overall picture.
If you’d asked me yesterday which benchmark is best for tracking progress towards a technological singularity, I would have said METR - software engineering time horizons as a proxy for progress towards full AI research automation.
Two weeks ago, in The Phase Shift, I quoted Chris Painter from METR:
“Our ability to measure capability is rapidly falling behind the pace of capability itself. The water might boil before we can get the thermometer in.”
The thermometer just broke.
METR estimates that Claude Opus 4.6 has a 50% time horizon of around 14.5 hours on software engineering tasks - the length of task a model can complete with 50% reliability. The 95% confidence interval runs from 6 to 98 hours. Their task suite is nearly saturated. They’re running out of problems hard enough to test these models.
For context, this graph was measuring ten-minute tasks a year ago. Six hours two weeks ago.
Fourteen and a half hours.
METR’s David Rein stresses the noise: shift the task distribution slightly and you’d measure 8 hours, or 20 hours. GPT-5.3-Codex came in at 6.5 hours, though METR flag potential scaffolding issues - Codex is more optimised for a particular scaffold than Opus is.
Oscar Sykes put it well: “Huge green flag for METR that the best pushback on their task horizon work consistently comes from METR themselves.”
The exact number is noisy. The direction isn’t.
Those data points do not line up with the 123-day doubling line no matter how much I squint. I’m quite confident of that.
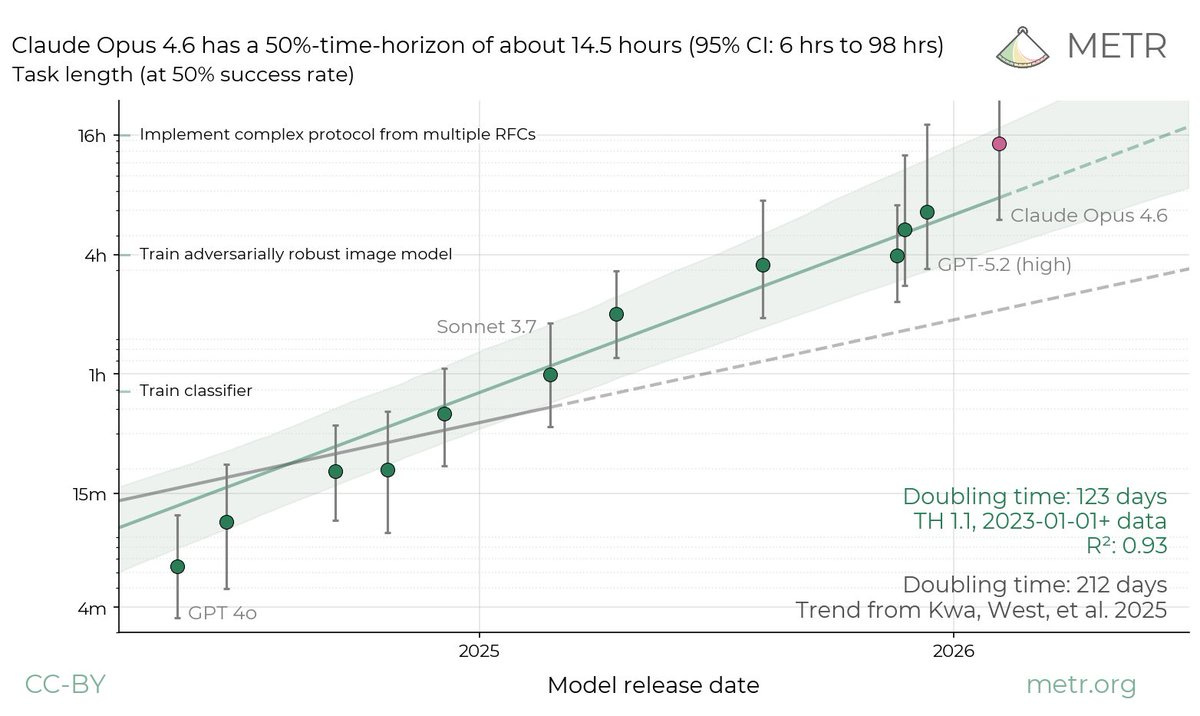
METR had a doubling time of 4.5 months two weeks ago. We’re now looking at three months, maybe less. That’s a big fucking change.
Three-month doubling time means three more doublings this year - or 120-hour time horizons by December. Five full working days of autonomous software engineering, at 50% reliability.
The trend may not hold, but I really don’t see the case for that clearly. I see a much clearer case for superexponential growth. It’s already happening.
This blows past predictions that seemed reasonable months ago. Ajeya Cotra - one of the most respected AI forecasters globally - predicted 24-hour time horizons at end of 2026. We may already be there, depending on which end of the confidence interval you trust. Two weeks ago, she estimated a 10% chance of full automation of AI research this year. I said 20% at the time. Even those numbers now look conservative.
And the people who were confidently calling this a sigmoid two weeks ago look deeply silly. In theory, you can never distinguish an exponential from the early part of a sigmoid. Which makes it perfect cope.
There’s a subtler dynamic at work in why the practical impact looks so dramatic.
If you have 1,000 steps in a process and a 1% failure rate per step, you succeed 37% of the time. Cut the failure rate in half - to 0.5% - and you succeed 61% of the time. You’ve “only” halved the error rate, but nearly doubled the success rate. That’s the O-Ring model. The last few pieces that lock into place are a huge unlock.
So yes - the jump in the METR number is partly about the metric saturating. This is an 8, not an 11. But that observation cuts both ways. It means small reliability improvements - getting rid of one common error type - now translate into massive gains in practical capability. Doing easy, relatively unimpressive things has the potential for impressive impact. The improvements can be “not out of line” with the historical trend, and that just tells you the trend line bends upward.
The METR graph isn’t the only measurement breaking.
Their previous study on AI-assisted developer productivity - which found a 20% slowdown when developers used AI tools - is now obsolete. They tried to run a follow-up in August 2025. Developers refused to participate, mostly because the expected productivity loss on “AI disallowed” tasks was too painful to bear. The original participants - the ones who experienced a 20% slowdown - now show an 18% speedup. And that data is already two capability cycles old. METR acknowledge their experimental design struggles to track work when participants use agents to parallelise across multiple tasks. The tool has evolved past the experiment’s ability to measure it.
The benchmark designed to track AI capabilities is being overwhelmed by AI capabilities. That is not a reason for comfort.
The Defense Analyses and Research Corporation called this “one of the most important national security stories of the day” and noted it would go “largely unremarked upon by nearly every Serious Defense Thinker in Washington - tells you everything you need to know about the quality of their forecasts of international affairs.”
Mark Beall: “It’s the same category of professionals who missed Pearl Harbor, 9/11, and nearly every other strategic surprise we’ve ever had.”
Some politicians are waking up. Bernie Sanders mentioned the METR plot at a town hall. Miles Brundage: “Politicians are bifurcating into those who have lost the plot on AI and those who cite the METR plot.”
Meanwhile our world leaders remain asleep at the wheel.
I put the probability of a technological singularity this year at 30% or higher.
In The Phase Shift, I described AI improving itself, safety mechanisms failing to keep pace, and the world not noticing. Two weeks later, the benchmark designed to measure that acceleration has saturated. The thermometer broke before the water finished boiling.
So the real question: how many more doublings before a hard takeoff? Because at this rate, we’ll find out before most people have noticed the question exists.